

世の中にあふれているカオスマップは、「実態を理解した人」による「きちんと整理」されたカオスマップではありません。
特にAIの分野においては、AI導入支援を行っている者からすると悲しくなるほど整理の仕方に違和感があります。もちろん製品の露出のために、とにかくマップに載せてもらっているという実情もありますが、きちんと整理をすることもAI導入を行う私たちの役割と思っています。
その違和感と使命感(!?)からチャットボットのカオスマップ、というよりはチャットボットをきちんと理解していただくための連載を開始し、今回で第4回目になります。
連載:チャットボットのカオスマップがカオスなのでちゃんと説明してみる
- Part.1 ~チャットボットとは、基本は「入力にヒットしたものを返す」~
- Part.2 ~非AI型でキーワードマッチ型について~
- Part.3 ~入力された文章を分解して応答を返す仕組み
- Part.4 〜文章の意図を理解して応答を返す仕組み
第3回の復習「形態素解析」
連載の第3回では、形態素解析・分解をするとより使えるチャットボットになる、そのためにはAIが必要という内容でした。「Googleのパスワードを忘れてしまった」を「Google パスワード 忘れ」として検索し、回答を持ってくるという方法でした。
 これにより自然文でもチャットボットは回答を返せるようになりましたが、「Google」が「グーグル」だったり、「忘れ」が「失念」だと回答は返せなくなります。
これにより自然文でもチャットボットは回答を返せるようになりましたが、「Google」が「グーグル」だったり、「忘れ」が「失念」だと回答は返せなくなります。
そこで活用するのが、類義語や言葉の関連性です。
「類義語」があればキーワードの表記揺れは吸収できる
本来の意味とは異なりますが、「類義語」は「Google=グーグル=ぐーぐる=GOOGLE」というように、置き換えて欲しいリストと理解しましょう。AIチャットボットにはこのようなアルファベットをカタカナで置き換える、正式名称を略語で置き換えるための辞書があり、その辞書は一般的には日々、更新されています。
この辞書を使えば、以下の図のように、「グーグル パスワード 忘れ」でも「Google パスワード 忘れ」と同じ検索ができるようになります。
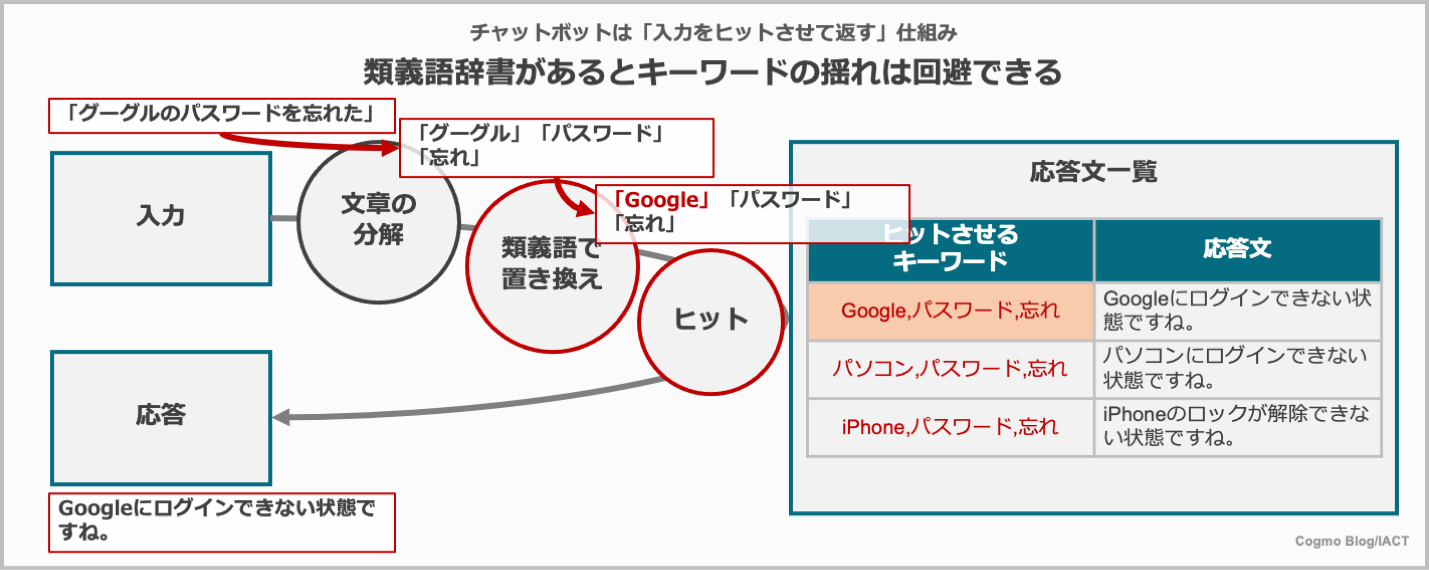
類義語は置き換えることで吸収。より揺れを吸収する仕組みが関連性
キーワードなどの単語の読み替えは、「Google=グーグル」などのように設定すれば良いのでAIが置き換え辞書を持っていればカタカナでもアルファベットでもヒットできます。もちろん、自分たちで設定することでもヒットできるようになりますし、会社内の独自の類義語、例えば製品正式名称と型式なども設定してヒットできるようになります。
ただ、「忘れる」という質問単語を、「失念した」「なくした」「わからなくなった」のように質問してくることもあります。この揺らぎを吸収するのには、類義語のように「忘れ=失念=なくす=わからない」という形で設定することもできますが、
- キーワードの置き換えより膨大になる
- 必ずしも等式(イコール)にはならない
という課題があります。
1の「キーワードの置き換えより膨大」になることは、システムだから時間をかけて大量な処理をやってしまえば良いのですが、2の「必ずしも等式(イコール)にはならない」のが課題となります。
例えば、「忘れ」にはモノを置いてきたという使い方(家に鍵を忘れた。家に鍵を置いてきた)もあり「忘れ=置いておく=失念=なくす=わからない」という等式(イコール)では結びつけられないものもあります。
これを解決する方法としては、イコール(=)ではなく、ニアリーイコール(≒)を使えば上手くいきます。実際には、ニアリーイコールではなくて、「単語A」と「単語B」の関連度はどの程度かという、単語間の関連性を数値で表現します。
これは、ある条件で単語Aと単語Bの出現率などを計算するやり方で、自然言語の分散処理や単語ベクトルなどというテーマで語られます。
一般に理解しやすいイメージとしては、単語Aと単語Bを結んだ線が太いか細いか、とイメージしていただければ結構です。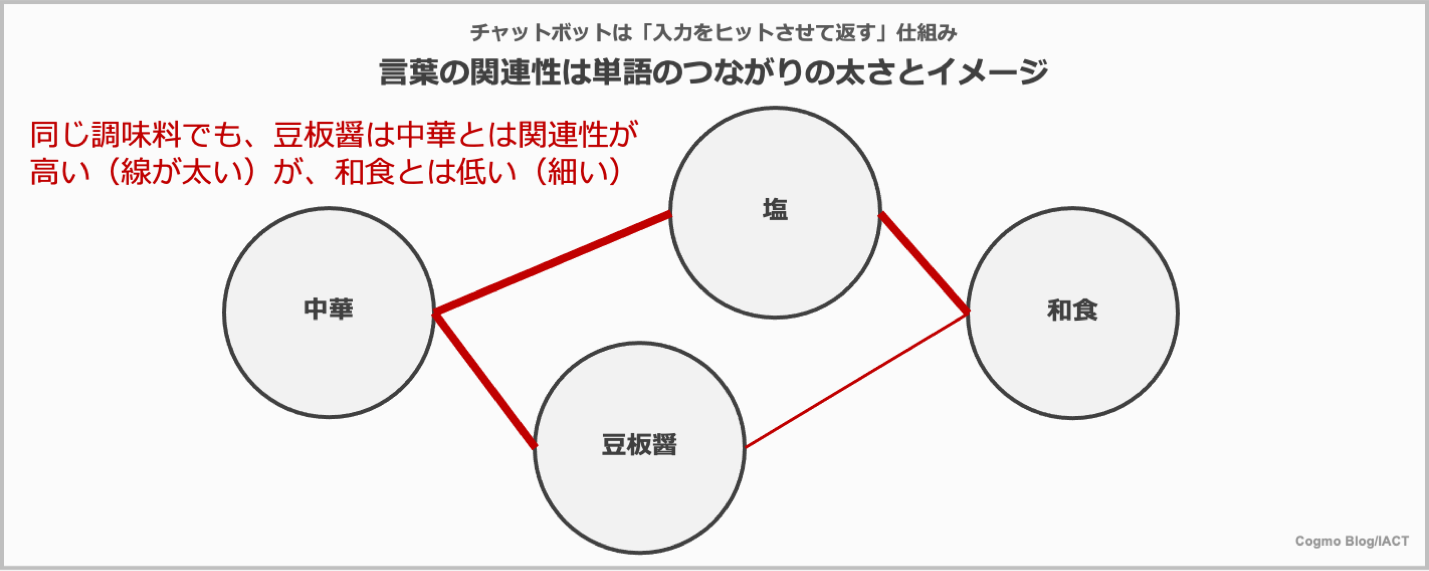
関連性は、大量の文章を解析することで作成される
単語Aと単語Bの関連性、例えば、「東京都」は「首都」か「地方」かと言えば、「東京都は首都である」が正しいので「東京都」は「首都」との関連性の数値が高くなる必要があります。これは、人が手作業で設定するのではなく、世の中にある文章を解析することで自動的にその関連性の数値を導き出しています。
例えば、「政府機関が東京都に集中している。危機管理やさまざまな観点から地方に分散させるべきだ」と「日本の政府機関は人口1400万人の首都に多く集まっている」というふたつの文章があります。
文章を解析するエンジンは、「である」は「is(イコール・=)」ということや、主語や述語に相当する単語(政府機関=主語、集中・分散・集まっている=述語)は何であるかなどは文の構造から判断できるようになっています。
このエンジンを使うと、「政府機関が東京都に集中している。危機管理やさまざまな観点から地方に分散させるべきだ」からは、以下のように、「東京都」は「政府機関」を中心に「集中」と「分散」という単語を通して、「地方」と結びつきます。
また、「日本の政府機関は人口1400万人の首都に多く集まっている」は、「政府機関」を中心に「集まっている」「首都」と「人口」、「1400万人」が結びつきます(「集中」と「集まっている」は同じ言葉であるでという関連性をAIが基本辞書で持っていれば(グレー線)、より結び付きは強くなります)。
これらの結び付きの強いところをたどれば、「東京都」は「首都」との単語の関連性が近いことがわかります。
このような関連性はAIが人が作成した文章、例えば、ニュース記事や、Wikipediaなどの辞書サイト、ブログなどの記事を、日々、取得しに行って読み込み、そこに書かれている文章の中にある単語の関連性を数値化することで出来上がっています。これが一般的にいわれるAI辞書になります。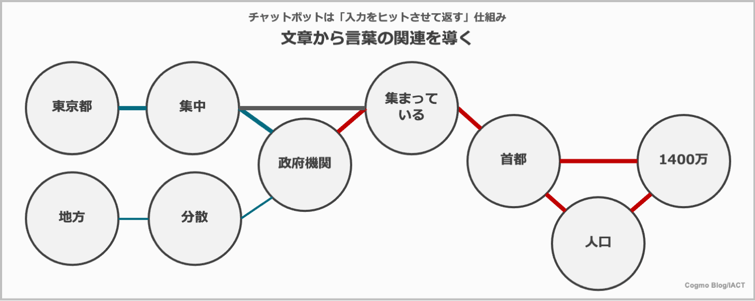
最初の文章からは青い線の結び付きが得られます。青の線は、「集中している」という現在の状態を述べていることと、「分散すべき」と今の状態ではないことを述べていることから、青の線の太さが違います。青の線だけでは「東京都」が「首都」とは分かりませんし、線をたどれば細い線ですが「地方」に結びつきます。ただ、次の文章の赤い線で「東京都」は「首都」であるとわかります。かつ、「東京都」は「1400万人」住んでいることもわかります。さまざまなたくさんの文章を解析することで、人の言葉の使われ方が数値化される(線の太さができる)ことになります。
関連性があれば、人の文章の揺れを吸収できる
このように作成された単語間の関連性を持つAI辞書があれば、「忘れ=置いておく=失念=なくす=わからない」といういびつな等式を人が設定しなくても、「忘れる」という単語と、「置いてきた」「失念した」「なくした」「わからない」という単語は近しい関係にあると計算できるようになります。
また、もうひとつの単語を組み合わせればもう少し複雑な判定をすることができます。
例えば、「パスワード」という言葉を加えると、世の中の文章に「パスワードを置いてきた」というような使い方はまずないので、「パスワード」と「置いてきた」の関連性は低くなります。
よって「パスワード」と「忘れる」の単語を組み合わせると、「わからない」「失念した」は関連度が高く、「なくした」はそこそこ、「置いてきた」は関連度が低いとなりそうなので、「パスワードを忘れた」「パスワードがわからない」「パスワードを失念した」は同じようなことを言っているのだろう、「パスワードをなくした」もそうかもしれない、「パスワードを置いてきた」は同じことではないな、とシステムで判定することができます。
この判定が計算で導き出せることでAIが人の質問を理解する、という仕組みが実現できるわけです。
AI辞書はあっても、学習は必要
AIは単語間の関連性を数値で持っており、一般的な文章を形態素に分解し、その形態素(単語)を使えば文章の意図を数値化できることを説明しました。
では、AIチャットボットなどは契約すればすぐに使えるかというと、そうではなく、学習が必要になります。これは、「意図の種類」を設定するという作業(学習)になります。
例えば、「請求」という言葉があります。
AI辞書は「請求」についての数値は持っていますが、実はこの数値はひとつの単純な数値ではありません。保険会社のシーンでは、契約者が入院したので保険金を請求するという使い方の請求と、保険会社が毎月の保険料を契約者に請求するという使い方の請求があります。
この場合、契約者が使う「請求」には、「いつ入金されるか」「いくら受け取れるか」などの言葉たちの関連性が高い一方、保険会社が使う「請求」には、「口座から引き落とされていない」「支払われていない」などの言葉たちの関連性が高くなります(そう使われている文章がたくさんある)。
同じ言葉でも使われるシーン、意図によって単語の関連性は変わり、単語の数値もひとつで表すことができなくなります。
よって、AIを言語の認識で使いたい場合は、どんなシーンがあるかということを「意図の種類」として設定し、その意図での単語の関連性・数値を決めさせてあげます。
具体的には、そのシーンで使われる質問文をいくつか登録します。
「Googleのパスワードを忘れた」時の質問文、「iPhoneのパスワードを忘れた」時の質問文、というような質問文をそれぞれ複数個登録していきます(この登録する個数を少なくし負担を下げられるなどがAI学習ディレクターのノウハウだったりします)。
このような登録をすることで、基本的な数値を持っているAI辞書をみなさま独自のシーンで使えるようできます。
さて、この「意図の種類」は、AIチャットボットでは、intent(インテント:意図)やclass(クラス)と呼ばれます(以降はintentと記述します)。このintentを、前回から説明しているExcelのヒットさせる列に使えば質問文の揺れを吸収して回答を出すことができる仕組みが出来上がります。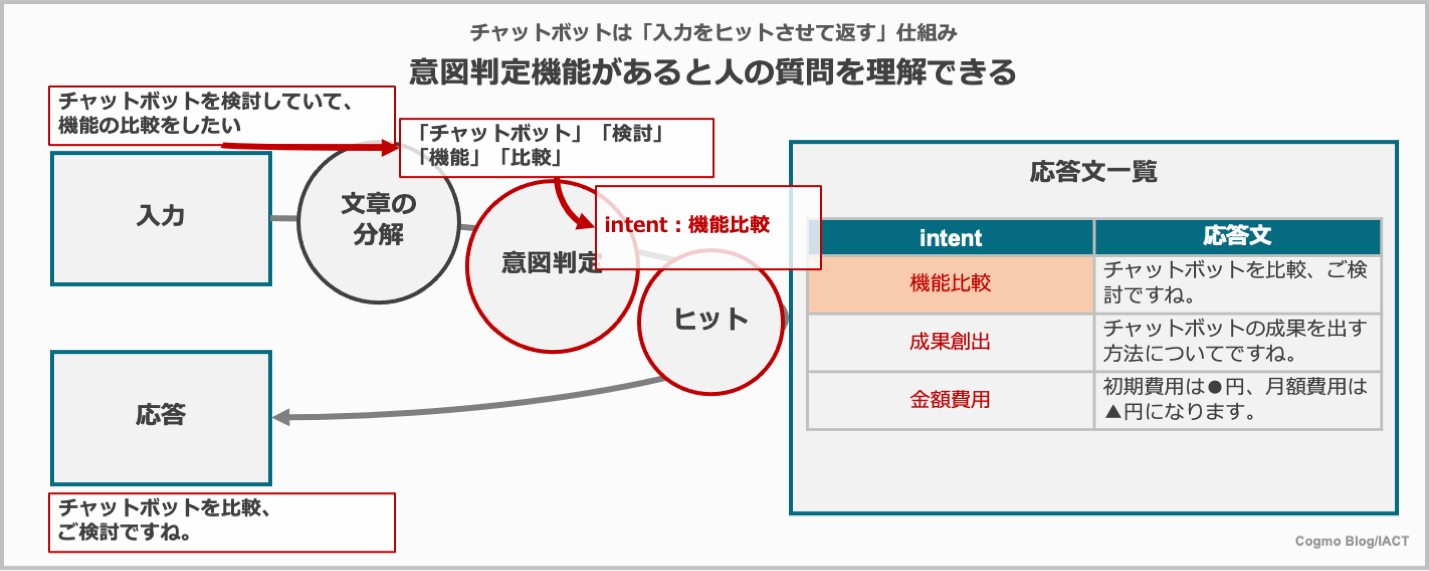
「チャットボットを検討していて、機能の比較をしたい」という文章は、形態素に分解され、学習されたAIによってどのintentかが判定されます。そして、intent:機能比較の時に答えるべき文章が応答され、ユーザは答えを得ることが出来ます。
「チャットボットを検討していて、機能の比較をしたい」ではなく、「chatbotの機能比較」でも「他社チャットボットの機能の違い」でもintent:機能比較が判定されれば同じ答えが返ってきます。
これが言葉の揺らぎや人の言葉の使い方を吸収して回答を返す仕組みになります。
そして、intent:機能比較と正確に、かつ、正しい幅広さ(揺らぎ)で判定されるようすることがAIチャットボットの学習作業と精度になります。
さて、これまでお伝えしたことで、AIチャットボットがどう動くのか、というのをご理解頂いたかと思います。次回からは、非AI型チャットボット、AI型チャットボット、事前学習済み型に有人チャットなどを加え、ツール選定の成功・失敗のこぼれ話も入れながら、私たちなりのカオスマップのフォーマットを作っていきたいと考えています。
※自然言語処理のベクトルの考え方などについては、一般的にわかりやすいように表現しております。