

はじめに
最近の AI の進化はすごいですよね。文章を伝えるだけで高品質な画像が生成できたり、人間のようにチャットで対話ができたりと、数年前では考えられなかったことがいろいろとできるようになってきました。
 最近の AI は絵も描ける!
最近の AI は絵も描ける!
しかし、これらの AI をみなさんの業務で使うのはまだまだ大変です。AI でできることが増えても、みなさんの業務はそれ以上に多種多様なので、話題の AI がそのまま業務にピッタリと当てはまることはまれでしょう。
業務で AI を活用するためには、もう少し AI の仕組みを知る必要があります。仕組みがわかれば「我が社の○○業務で利用できるかも?」という想像もしやすくなりますし、AI の苦手なことが想像できれば PoC(Proof of Concept:実現可能性の検証作業)で無駄なコストを使ってしまうことも防げます。
そこでこの記事では、AI の仕組みを知っていただくために「そもそも AI とは一体なんなのか?」についてわかりやすく解説します。
途中に少しだけ専門用語や数式、プログラムらしきものが出てきますが、読み飛ばしても大丈夫な部分はこの文字色で 🙈読み飛ばしOK! のマークを入れています。小難しい話は適当に読み飛ばしつつ、最後までお付き合いいただけますと幸いです。
目次:
- 第 1 章 AI はなぜ人間みたいなことができるのか?
- そもそも AI とはなにか?
- AI はどうやって人間みたいなことをするのか
- 人間が考えた「解法」をコンピューターで実行する方法
- 「解法を考えること」までコンピューターで実行する方法
- 第 1 章のまとめ
- 第 2 章 脳
- 脳のすごいところ
- 脳の仕組み
- 脳をマネしたら?
- 1 個の細胞でいろいろできる
- あいまいな判断もできる
- 細胞が 3 個あると XOR もできる
- 細胞が 160 個あると 手書き数字も認識できる
- 第 2 章のまとめ
- 第 3 章 伝わりやすさと境界の決め方
- とりあえず 1 か所だけ調整
- 値をすべて調整
- さまざまなバリエーションで調整
- 少しずつ何度も調整
- 実際の調整の工夫
- 第 3 章のまとめ
- 第 4 章 課題とそれに対する取り組み
- いろいろな細胞とそのつなげ方
- 細胞のつなげ方の例
- 用途の異なる仕組みを組み合わせる例
- 第 4 章のまとめ
- 第 5 章 会話の仕組みとその活用
- 文章を生成する技術の進化
- 仕組みの大規模化
- 会話の実現
- 会話による AI の利活用
- 第 5 章のまとめ
- おわりに
・
・
・
第 1 章 AI はなぜ人間みたいなことができるのか?
そもそも AI とはなにか?
AI とは「artificial intelligence」の略です。日本語だと「人工知能」となり、コンピューターで人間みたいなことを実現するための仕組みを指します。(厳密には、そのための技術や研究分野を指す言葉としても使われます。詳しくは 🔗Wikipedia「人工知能」をご参照ください。)
この第 1 章のタイトルにした「AI はなぜ人間みたいなことができるのか?」の答えは、「人間みたいなことができるものを AI と呼ぶから」です。
卵とニワトリのような話になってしまったので、もう少し踏み込みます。
AI はどうやって人間みたいなことをするのか
AI の目的は簡単に言えば「人間のマネ」です。現在の AI は、人間のマネのさせ方によって、大きく次の 2 つに分類できます。
人間が考えた「解法」をコンピューターで実行する方法
1 つ目は、人間が考えた答えの求め方(解法)をコンピューターに実行させる方法です。解法通りに計算するプログラムを開発し、それをコンピューターに実行させることで実現します。
たとえば、ある会社の過去の売上と宣伝費の関係が次の表の状態だったとします。この時、売上 500 万円を達成するために必要な宣伝費はいくらぐらいになるでしょうか。
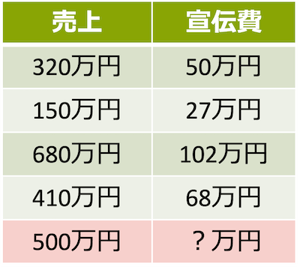
これは、線形単回帰分析と呼ばれる解法通りに計算すれば予測できます。うれしいことに必要なプログラムは Excel の分析ツールに組み込まれていますので、それを使えば解法の勉強や計算は必要ありません。上の表から下のようなグラフを簡単に描くことができ、必要な宣伝費は 80 万円弱くらいと予想することができます。
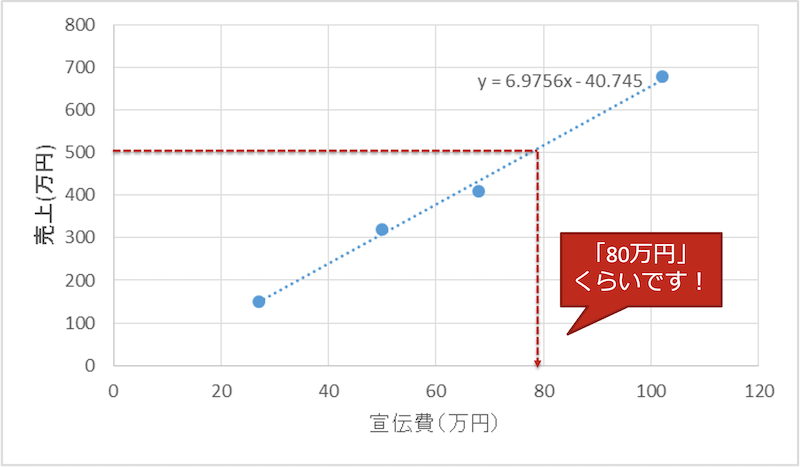
この場合、コンピューター(この例では Excel )は人間が考えた線形単回帰分析の解法をプログラムに従って実行しているだけになります。
「解法を考えること」までコンピューターで実行する方法
人間のマネのさせ方のもう 1 つは、「解法を考えること」までコンピューターで実行する方法です。たとえば、次のような手書き数字の画像に対して、その画像に書かれた数字を認識することを考えます。

この手書き数字を認識する解法を考えるのはかなり大変です。たとえば、「画像の中央部分で縦方向の黒い点が連なっており、かつ、それ以外の部分には白い点しかない場合に『1』と判定する」といったような手順を細かく考えていく必要があります。
以前はこのような手順を考えることで解法を作りコンピューターで処理していたこともありました。しかし最近では、解法を考えるのが大変な課題の場合に、その考える作業までコンピューターに実行させてしまう機械学習やディープ ラーニングと呼ばれる方法が主流になってきました。
第 1 章のまとめ
コンピューターで人間みたいなことを実現する方法は、大きく 2 つあります。1 つは人間が見つけた解法をコンピューターに実行させる方法で、もう 1 つは解法を考える部分までコンピューターで実行する方法です。
前者は人間が考えた解法をプログラムで動かしているだけなので、AI とは呼べないと思われる方もいらっしゃるかもしれません。しかし、2000 年ごろまでの AI はこのような形が主流でした。また、今でも人間が考案済みの解法で解決できる課題はたくさんありますので、課題に応じて新旧の AI を使い分けることが大切です。
第 2 章からは、後者の「解法を考える部分までコンピューターで実行する方法」について解説していきます。
・
・
・
第 2 章 脳
「解法を考える部分」をコンピューターに実行させるのは、とてつもなく大変でした。
80 年前の奇想天外な発想を起点に研究者による多くの挑戦と失敗が繰り返され、ようやく 20 年くらい前から実用化され始めたのです。この章では、その奇想天外な発想と、それがどのようにコンピューターで実行されているのかを解説します。
脳のすごいところ
突然ですが、人間の脳はすごいです。
- 計算できる
- 読める・書ける
- しゃべれる
- 絵だって描ける
- 知識や経験で判断できる
- 将来の予想もできる
- 経験や訓練で効率が上がる
- できることが勉強で増やせる
当たり前のように思われるかもしれませんが、コンピューターではこうはいきません。コンピューターはプログラムされたことしか実行できないので、できることを増やすにはプログラムの追加や修正が必要です。
脳は産まれた時にできた 1 つの仕組みで、経験や訓練をすれば性能が上がり、勉強すればできることが増やせます。これはすごいことなのです。
脳の仕組み
脳は、神経細胞と呼ばれる特殊な細胞がつながりあってできています。下の図の黄色い部分が 1 つの細胞です。
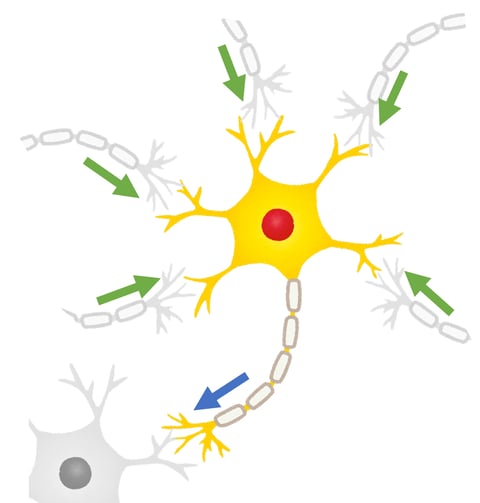
細胞は他の複数の細胞から信号を受け取ります。この図では、他の5つの細胞から緑の矢印の方向で信号を受け取っています。信号を受け取った細胞は、その強さの合計がある境界を越えると、次の細胞へ信号を伝えます。青い矢印がそれを示しています。
細胞間の信号の伝わりやすさや、次の細胞へ信号を伝えるかどうかの判断の境界は、細胞によってまちまちです。
脳をマネしたら?
1943 年に神経生理学者・外科医のマカロックさんと論理学者・数学者のピッツさんがタッグを組み、脳の神経細胞をコンピューターでマネした仕組みを考えました。脳の仕組みを調べてコンピューターでマネすれば、人間と同じように思考できる AI が完成するはず!そんな奇想天外なアプローチです。

ここで考案された仕組みは非常にシンプルです。
下の図の中央の青の丸が 1 つの細胞です。左側の 2 つの細胞から信号を受け取りますが、途中の緑の線で伝わりやすさの影響を受けて、伝わる信号の強さが変化します。それらを受け取った青の細胞は、受け取った信号の合計が境界を越えたら次の細胞に信号を伝え、越えない場合は何もしません。
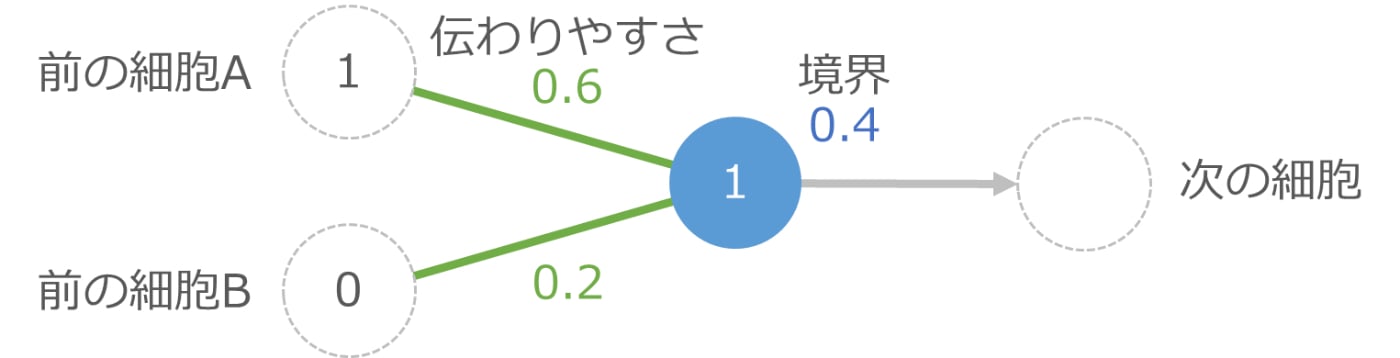
たとえば前の細胞 A から強さ 1 の信号が伝えられ、細胞 B からは強さ 0 の信号(つまり信号は伝えられなかった)とします。この時、上の図では細胞 A からの伝わりやすさは 0.6 なので、実際に伝わる信号の強さは 1×0.6 で 0.6 です。細胞 B からは信号がないので計算不要ですが、もし計算するのであれば 0×0.2 で 0 の信号が伝わった形です。
青い細胞は細胞 A から 0.6 、細胞 B から 0 の信号を受け取るので、信号の合計は 0.6 です。これは青い細胞の境界である 0.4 以上なので、次の細胞に強さ 1 の信号を伝えます。もし境界より小さい場合は、次の細胞には信号を伝えません。
これをプログラムで書くと次のような感じになります(プログラムの細かな理解は不要ですので、なんとなく眺めて次に進んでください)。
if (1 * 0.6 + 0 * 0.2 >= 0.4):
出力 = 1
else:
出力 = 0
1 個の細胞でいろいろできる
脳をマネしたこの小さなプログラムは、かなりいろいろなことができます。
たとえば、伝わりやすさと境界をうまく調整すると、論理演算と呼ばれる計算の中の AND と OR と NAND の機能が 1 つの細胞で実現できてしまいます。
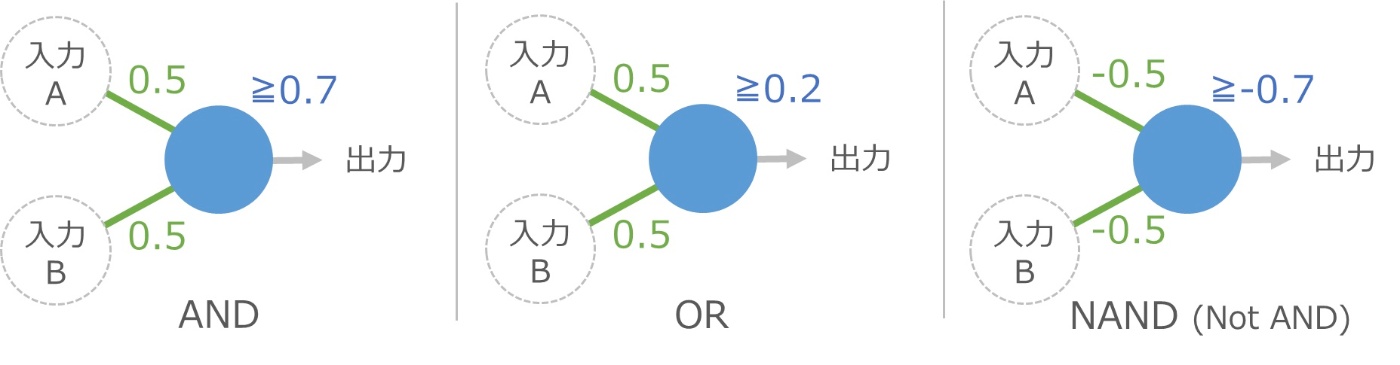
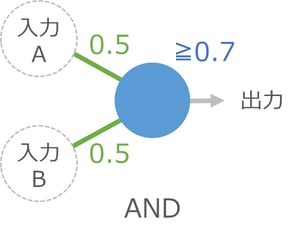
AND とは、両方の入力が 1 なら出力は 1 、それ以外は 0 という計算です。上の図で入力AとBが 1 の場合、青い細胞には 1×0.5+1×0.5 で合計 1 の信号が伝わり、境界の 0.7 以上なので出力が 1 になります。もし細胞Bが 0 の場合は、1×0.5+0×0.5 で合計 0.5 となり、境界に届かないので出力は 0 です。
OR は、どちらかが 1 なら出力も 1 になる計算です。同じ感じで計算できますね。
NAND は AND の逆の結果を返します。これは少し特殊で、右上のように伝わりやすさと境界にマイナスの値を使うと実現できます。伝わりやすさがマイナスというのはちょっと違和感がありますが、細かいことは気にしないで進みましょう。
ここで重要なのは、次のような1つのプログラムで、■の値を変えるだけで 3 つの機能が実現できることです。
if (入力A * ■ + 入力B * ■ >= ■):
出力 = 1
else:
出力 = 0
これまで、機能を追加するにはプログラムの追加や修正が必要だったのですが、決められた箇所の値を変えるだけならプログラムの修正は必要ありません(変数やパラメーターという仕組みによりプログラムを変えずに指定できます)。この 1 つのプログラムで、AND も OR も NAND も計算できてしまうのです。
あいまいな判断もできる
このプログラムがおもしろいのは、入力が多少あいまいでも大丈夫なことです。
たとえばキャンプに出発する条件が「明日と明後日の天気が晴れなら」だったとします。これをコンピューターに判断させる場合、明日と明後日が晴れかどうかを入力して AND を計算させる形になります。

人間なら明日の降水確率が 10% で明後日の降水確率が 20% でもキャンプに行くかと思いますが、コンピューターはこの辺の融通がなかなか効きません。AND を計算する時に、晴れる確率として 0.9 と 0.8 を渡して AND を計算させようとしても普通は計算できません。AND の計算は入力が 0 か 1 という前提があるためです。
ところが、今回の細胞をマネしたプログラムでは、入力に 0.9 と 0.8 を渡しても計算できます。
青い細胞への入力は 0.9×0.5 + 0.8×0.5 = 0.85 になって 0.7 以上なので、無事キャンプへ出発できます。このように、伝わりやすさや境界の値の調整によって、あいまいなデータでも処理できるところがポイントです。
細胞が 3 個あると XOR もできる
細胞 1 つでは論理演算の XOR は計算できないのですが、細胞が3つあると実現できます。XOR はどちらかの入力が 1 なら出力が 1 、ただし両方 1 の場合は 0 になる計算です。
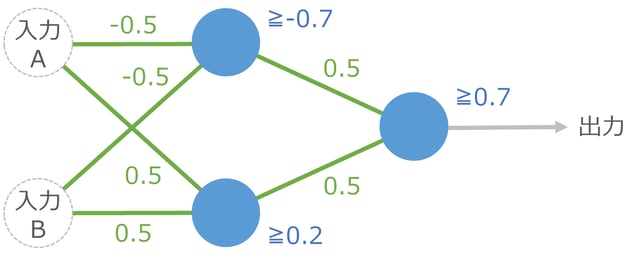
入力 A からは 2 つの青い細胞に信号が伝わります。入力 B からも同様です。それらを受け取った 2 つの細胞は、右の 1 つの青い細胞に出力を伝えます。このような 2 段階の計算を経て最後の出力が決まります。
実際に入力 A と B に値を指定して計算してみると、XOR が実現できていることがわかります。
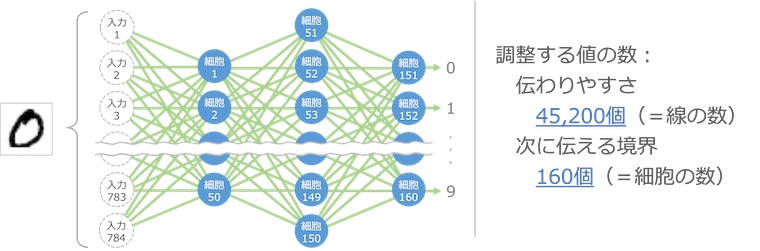
細胞が 160 個あると 手書き数字も認識できる
細胞を 160 個使って次のように組み合わせると、なんと手書きの数字が認識できてしまいます
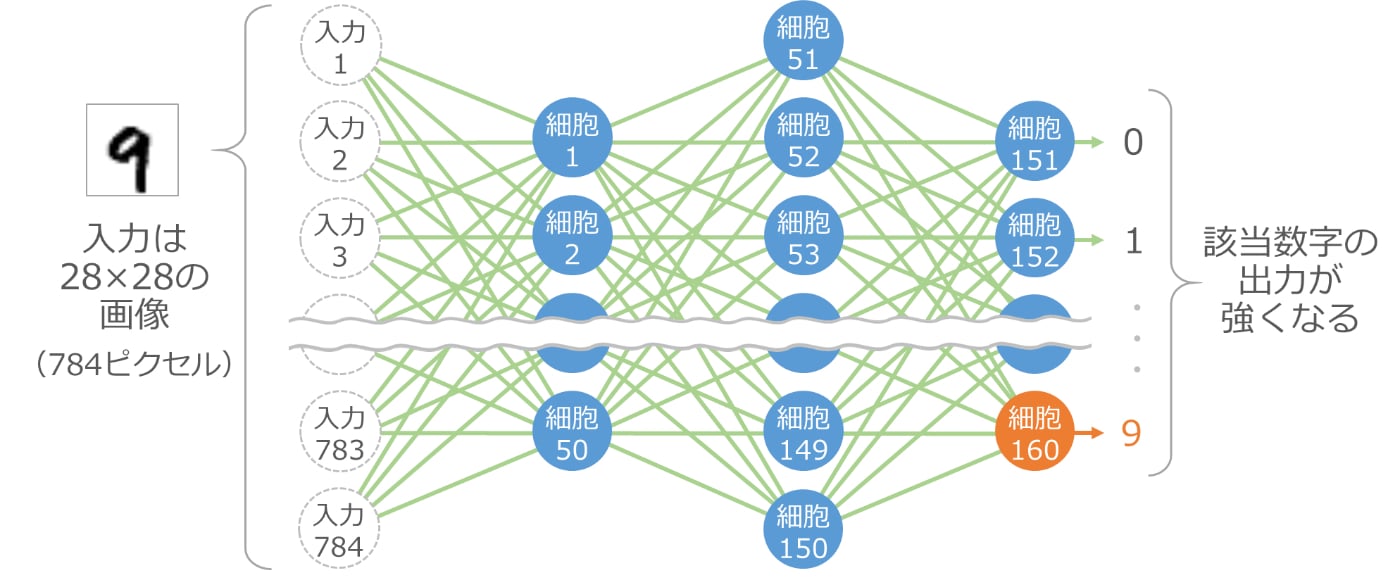
入力は 784 個のデータで、縦横 28 ピクセルの画像データです。これを入力データとして、50 個(細胞 1 から細胞 50)の細胞の出力を計算します。次にこの50個の出力を入力として、次の 100 個(細胞 51 から細胞 150)の出力を計算します。最後にこの100 個の出力を入力として、最後の 10 個(細胞 151 から細胞 160)の出力を計算します。
最後の 10 個の細胞は数字の 0 から 9 に対応しており、入力で渡した画像に対応する数字の細胞の出力が強くなる仕組みです。これにより、手書き数字の画像がどの数字なのかを認識できます。
🙈読み飛ばしOK!
この仕組みで、MNIST データベースと呼ばれる手書き数字画像のデータセットで 90% を越える認識精度を出すことができます。
しかし、入力の 784 ピクセルのデータをすべて同じように細胞 1 から細胞 50 へ全結合(アフィン結合と呼ばれます)しているため、実際のピクセル同士の位置関係が失われてしまい、精度を上げにくい構造になっています。
そこで、このような画像認識の処理では、ピクセルの近いもの同士だけを次の細胞につなげる「畳み込み」(コンボリューション)という仕組みや、関連するピクセルの関係を保持できるように細胞のつなぎ方を工夫した「注意機構」(attention)という仕組みがよく使われます。細胞のさまざまなつなぎ方については第 4 章でもご紹介します。
このように、細胞を組み合わせていろいろなことができるようにした仕組みのことを「ニューラル ネットワーク」(neural network)と呼びます。
第 2 章のまとめ
- 脳の神経細胞をマネすると、細胞間の信号の伝わりやすさと次へ伝える境界の値を変えるだけでできることが増やせます。
- 細胞を増やせば、複雑なこともできるようになります。
ここで問題になるのは、細胞間の伝わりやすさと次へ伝える境界の値をどうやって決めるのか?です。AND や OR くらいならまだ考えることができますが、細胞が 3 つになった XOR はかなり難しいですよね。手書き数字の認識みたいな話になると、とても考えられそうにありません。 どうやって値を決めればよいのでしょうか。
・
・
・
第 3 章 伝わりやすさと 境界の決め方
第 3 章では、細胞間の伝わりやすさと境界の値の決め方について、手書き数字の認識を例に解説します。
とりあえず 1 か所だけ調整
まず、伝わりやすさや境界の値を、適当なランダムの値にしておきます。そして、手書き数字の 0 の画像を 1 枚渡して出力を計算します。
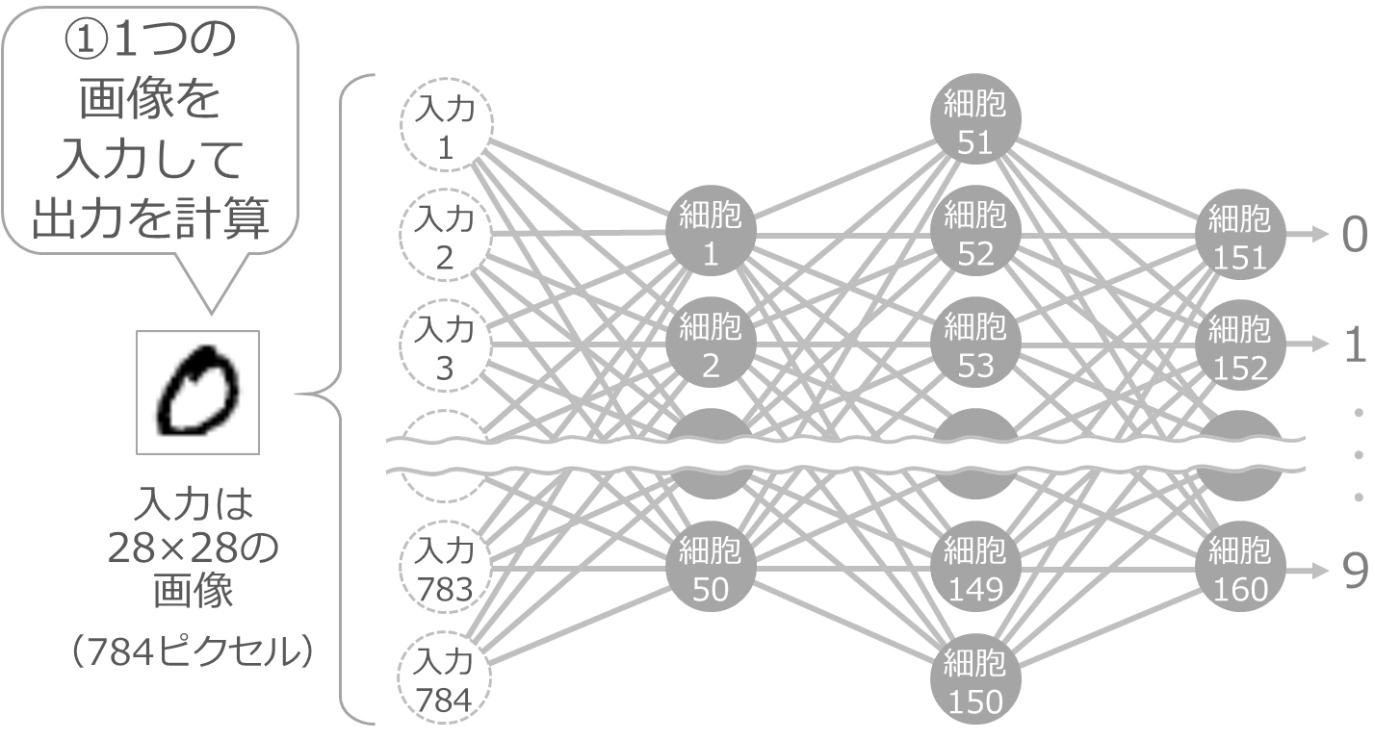
値がランダムなので、当然ながら正しい出力にはなりません。おそらく、最後の 10 個の細胞はどれも同じくらいの出力になるかと思います。
次に、入力 1 と細胞 1 をつなぐ線の伝わりやすさの値を、少しだけ大きくしてみます。以下の青い線の部分です。
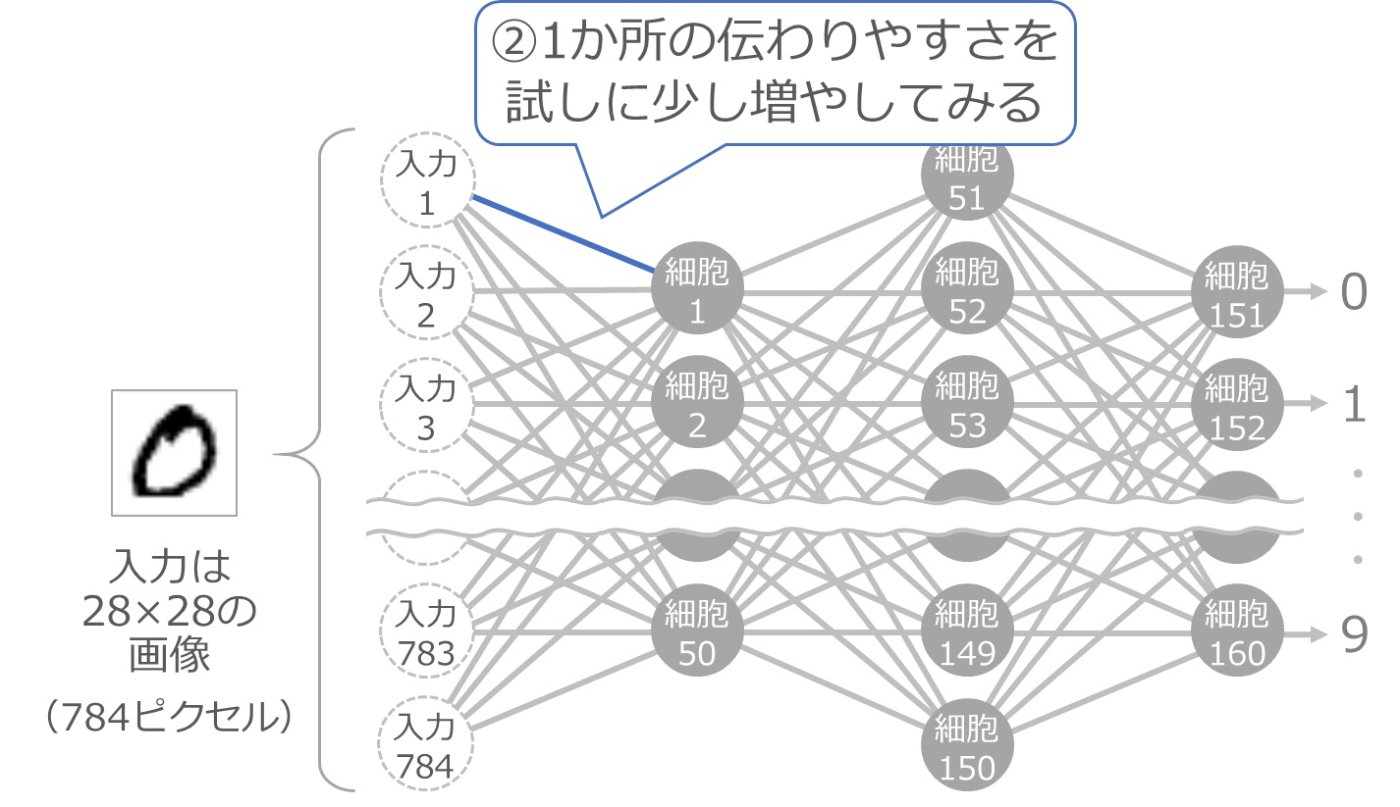
少し大きくすると、それ以降の細胞の入力が変化しますので、その部分の計算をやり直します。以下の青い細胞と緑の線の部分が計算のやり直しです。
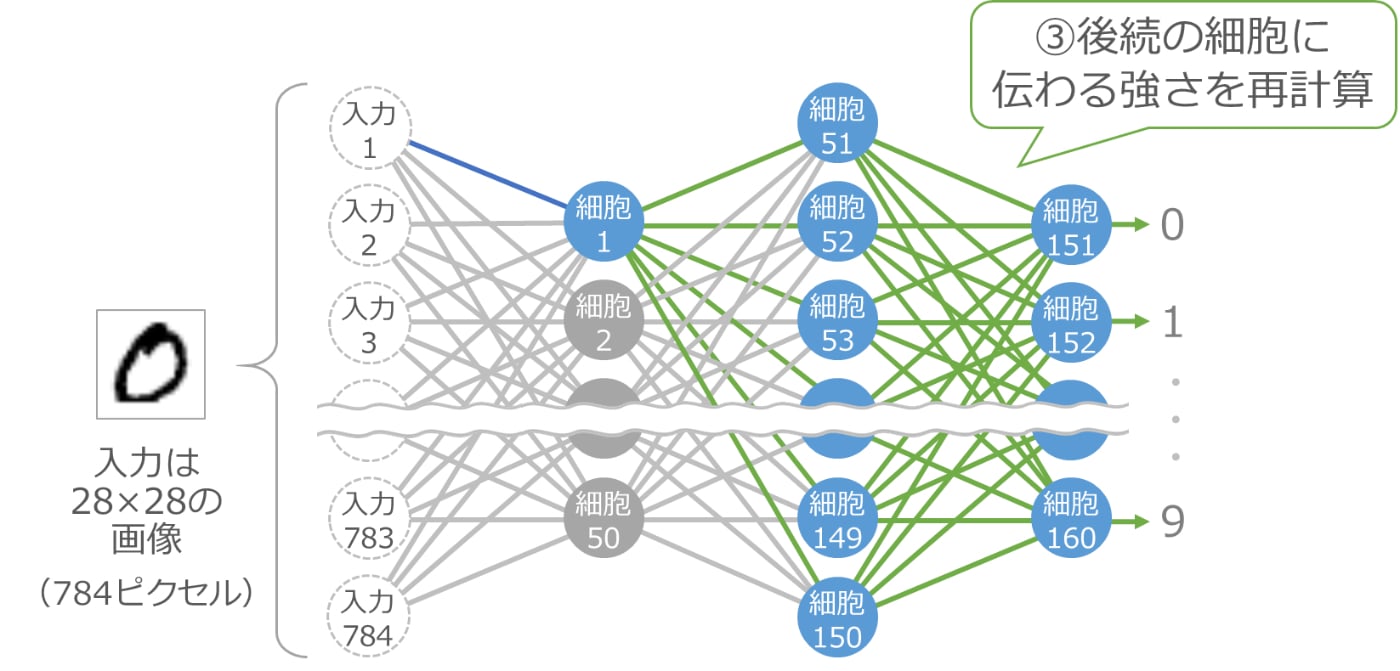
ここで、最後の 10 個の細胞の出力をチェックします。今は 0 の画像を渡しているので、理想は 0 に対応する細胞 151 の出力が大きくなって、他の細胞の出力が小さくなることです。そのように変化したかどうかをチェックするわけです。
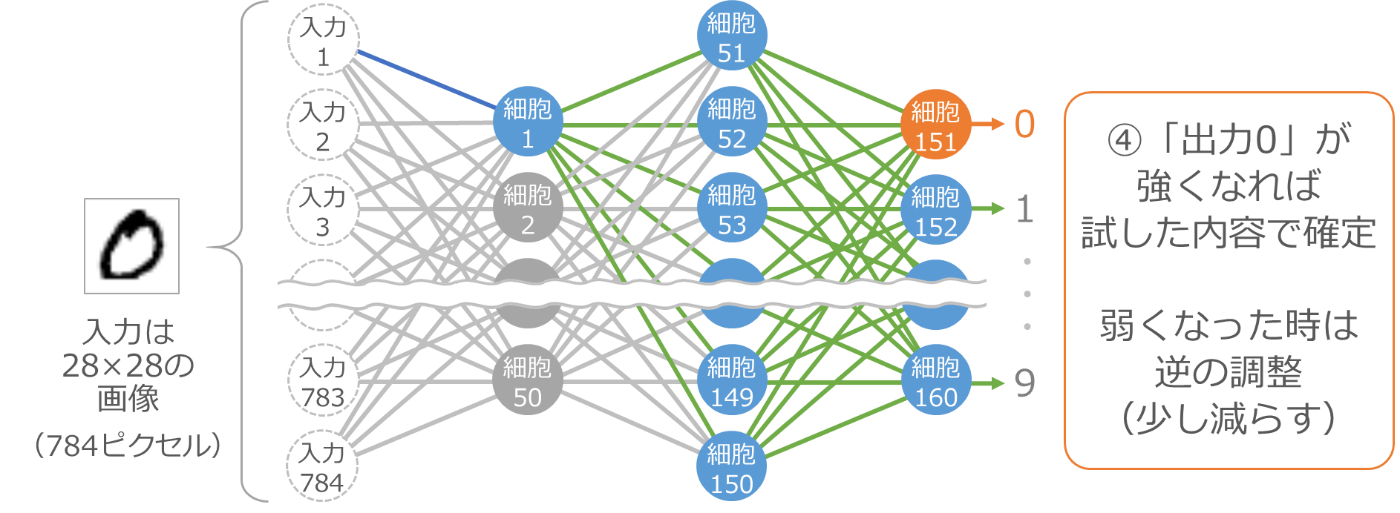
もし、細胞 151 の出力が最初に試した時より大きくなったり、他の細胞の出力が小さくなった場合は、入力 1 と細胞 1 をつなぐ線の伝わりやすさを大きくしたことが正解だったので、この値の変更を確定します。そうではない場合は、この値の変更は失敗だったので、逆に少し小さくすることで確定します。
値をすべて調整
同じ要領で、すべての伝わりやすさと境界の値を調整します。45,200個の伝わりやすさと160個の境界が対象です。
0 以外の画像でも調整
数字は 0 だけではないので、1 から 9 の画像も用意して同じ要領で調整します。
さまざまなバリエーションで調整
手書き数字はいろいろなバリエーションがあるので、各数字の手書き画像をたくさん用意して同じ要領で調整します。
少しずつ何度も調整
いろいろなバリエーションをバランスよく認識できるようにするためには、少しずつの調整を何度も繰り返す必要があります。そのため、用意した画像に対して何度も調整を繰り返し、調整しなくてもだいたい目的の出力が得られるようになったところで止めます。
かなり大変な作業になりますので、人間ではとてもできません。そこで、この作業を実行するプログラムを作り、コンピューターで実行します。このように、目的の出力になることを目指して何度も何度も少しずつ値を調整していく作業を「学習」と呼び、それをコンピューターに任せることを「機械学習」と呼びます。
なお、機械学習という言葉は最近よく耳にするようになりましたが、実は脳をマネする仕組み以外でも昔から使われている方法です。
🙈読み飛ばしOK!
実際の調整の工夫
値の調整はたとえコンピューターでも莫大な時間がかかるため、実際にはいろいろな工夫をしています。その工夫の例を 3 つ簡単にご紹介します。
a.細胞が出力する値の決め方
各細胞は入力の合計が境界以上なら 1 を出力するとご説明してきましたが、実際には 0 か 1 のどちらかではなく、なだらかな出力をしています。
0 か 1 のどちらかにしてしまうと、調整によって前の細胞からの入力の合計が A から B に変化しても、境界をまたがないと出力が変化しません。出力が変化しないと、そこから先の細胞への入力も変化せず、その調整の正否が判定できなくなってしまいます。下のグラフの緑の線がそれを示しています。
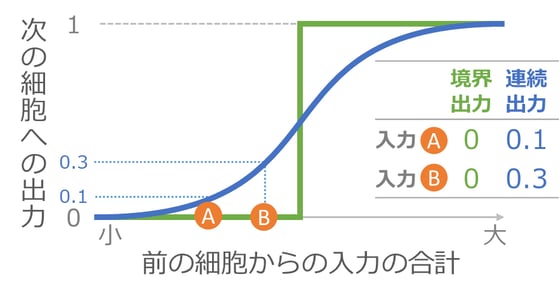
そこでグラフの青い線のように、入力の合計に応じて出力がなだらかに変化する仕組みを使います。こうすれば、入力の合計が A から B に変化した時も出力が変化し、いつでも調整ができるようになります。
b.偏微分の利用
値の調整は、最終の出力がどう変化するのかを確認しながら実施するため、何度も最終の出力を再計算する必要があります。しかし、細胞の数が増えてくると計算量が現実的ではなくなってしまいます。
そこで、少し数学の話になってしまいますが、偏微分という仕組みを使います。偏微分は式の中のある値が変わった時に、その式の結果がどう変化するのかを調べるための仕組みです。最終結果を求める式が偏微分できれば、最終結果を再計算しなくても各値が調整できるようになるわけです。
詳細は割愛しますが、最終結果を求める式を偏微分できるように組み上げることで、調整作業を大きく効率化しています。
c.行列計算の利用
出力の計算には、各細胞の出力と伝わりやすさの大量の掛け算、そしてその結果の大量の足し算を何度も繰り返す必要があります。これは、少し工夫すると行列の計算に置き換えることができます。
行列計算は、画像処理に特化した GPU と呼ばれる演算装置が得意なので、GPU を活用することにより調整にかかる時間を大きく短縮しています。また、最近では AI 専用の演算装置も開発され普及し始めています。
余談ですが、AI の普及に伴い行列の理解の重要度が増しており、文部科学省では一時期高校の数学から外れていた行列を 2022 年に数学 C として復活させています。
第 3 章のまとめ
- 細胞を増やせば複雑なことができます。
- 細胞が増えれば増えるほど大量の値の調整が必要になります。この調整作業を学習と呼び、それをコンピューターで実行することを機械学習と呼びます。
細胞を増やして機械学習すればなんでもできそうなご説明になってしまいましたが、実際にはそれほど甘くはなく、いろいろな課題があります。そこで第 4 章では、その代表的な課題と、それに対する取り組みをご紹介します。
・
・
・
第 4 章 課題とそれに対する取り組み
細胞を増やして機械学習すれば複雑なことができるようになります。この方法はディープ ラーニングと呼ばれ、AI ブームを巻き起こしました。
しかし、細胞の数が増えれば増えるほど機械学習には膨大なマシンパワーや時間が必要になります。精度を上げるためには機械学習に使う大量のデータも必要です。また、世の中には単純に細胞を増やすだけでは解決できないテーマもたくさんあります。
これらの課題を解決するために、細胞そのものの仕組みを改良する研究や、細胞間のつなげ方の研究、他の用途で作った仕組みを組み合わせる研究などが活発に行われています。
いろいろな細胞とそのつなげ方
以下のサイトで、FJODOR VAN VEEN さんが主要な仕組みをイラストで紹介しています。ページの先頭にある「Neural Networks」というイラストを軽く眺めてみてください。
🔗THE NEURAL NETWORK ZOO - THE ASIMOV INSTITUTE
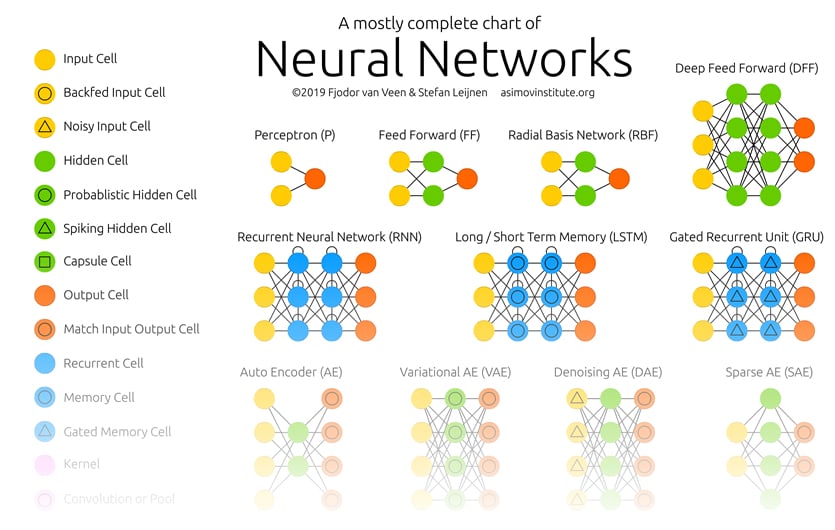
これは、主要な細胞の種類とつなぎ方をイラストにしたものです。カラフルな丸が細胞なのですが、いろいろな種類のあることがわかります。また、細胞のつなぎ方も、総当たりだったり間を飛び越していたり循環していたり、いろいろなつなげ方のあることがわかります。
細胞のつなげ方の例
細胞のつなげ方の例として、細胞の入力を計算する際に、前回計算した自身の出力も混ぜて使う仕組みをご紹介します。
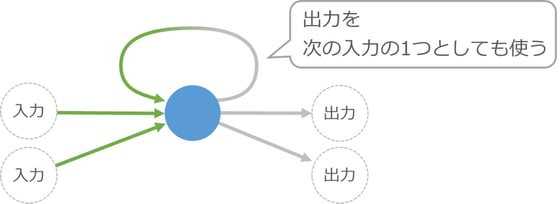
この図だけでは分かりにくいのですが、これで入力の順番を考慮した調整ができるようになります。たとえば、この細胞を使った仕組みに対して実際の小説のデータを機械学習させると、おもしろいことができるようになります。
まず、入力に小説の先頭の単語を与えて、出力がその次の単語になるように調整します。夏目漱石の「吾輩は猫である」の場合、まず「吾輩」を入力して出力が「は」になるように調整し、次に「は」を入力して出力が「猫」になるように調整していきます。
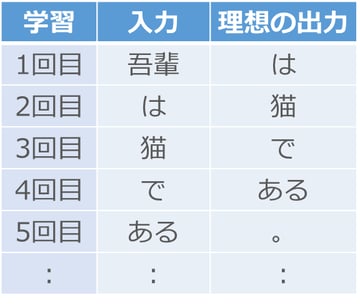
ここでのポイントは、小説の内容通りの順番で単語を入力して調整することです。出力を自分自身に戻す仕組みがあるため、たとえば2回目の「は」→「猫」の調整では、いつでも「は」がきたら「猫」が正しい、と調整されるわけではなく、1回目の「吾輩」の調整で使った細胞の出力が2回目の「は」の入力と混ざることで、「吾輩」と「は」が続く時は「猫」が正しい、という形で調整が進みます。
夏目漱石のさまざまな小説を使ってこのような機械学習を完了させると、小説の書き出しを適当に与えるだけで、続きを執筆してくれる仕組みができあがります。
まず入力に「吾輩」を与えます。何か単語が出力されますが、それは無視して次に「は」を入力します。同じように出力の単語は無視して「犬」を入力します。ここから先は出力で得られた単語をそのまま次の入力として与えていきます。
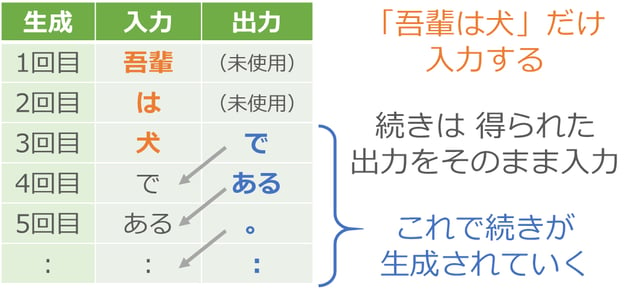
つまり「吾輩は犬」という書き出しを与えたら、あとは得られた出力をそのまま入力に回すことで、次々に文章を生成させていくわけです。夏目漱石の小説には「吾輩は犬」で始まる文はないかと思いますが、脳をマネた仕組みはあいまいな処理ができるので、夏目漱石風の新しい小説を執筆してくれます。
🙈読み飛ばしOK!
ここでご紹介した、細胞の出力を次の自身の入力に使うつなぎ方を「リカレント ニューラル ネットワーク」(recurrent neural network)と呼び、文章のような順番に意味のあるデータで使われる仕組みの 1 つになっています。
なお、単語は長さが一定ではないため、そのままでは手書き数字の例のように固定数のデータとしての入力ができません。そのため、2022 年時点では「単語の埋め込み」(word embedding)という手法などにより、その単語の特性を表現する固定数のデータに変換してから処理するのが一般的です。
このように、大量のテキスト データを使って文章が生成できるように機械学習した仕組みを「言語モデル」(language model)と呼びます。
用途の異なる仕組みを組み合わせる例
用途の異なる仕組みの組み合わせの研究も活発です。ここではその例として、文章を生成したり絵を描いたりする「ジェネレーティブ AI」と呼ばれる仕組みについて簡単にご紹介します。
[画像分類]+[文章生成]=画像の説明文を生成!
画像を渡すと 1,000 種類(たとえば「ペンギン」、「消防車」、「オレンジ」、「電球」など)に分類する VGG16 という仕組みがあります。縦横それぞれ 224 ピクセルのカラー画像を渡すと、その画像が 1,000 種類の中のどれなのかを識別し、何が写っているのかを教えてくれます。手書き数字の認識の発展版のような仕組みです。
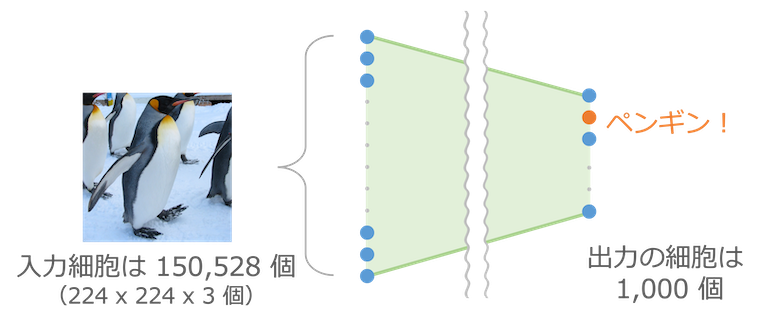
最終出力の 1 つ手前には 4,096 個の細胞が並びます。この 4,096 個の細胞の出力が最後の 1,000 個の入力になっているため、この 4,096 個の細胞の情報を使って最後の分類が行われています。つまりこの 4,096 個のデータには、その写真が何であるかを判定するために必要な情報が凝縮されていることになります。
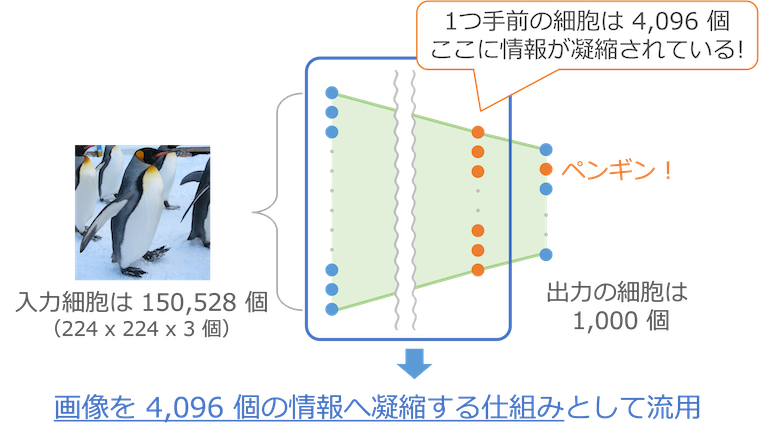
そこで、150,528 個ものデータからなる1枚の画像を、特徴を凝縮した 4,096 個の小さなデータへ変換する仕組みとして上の図の青枠の部分を流用し、先ほどの文章生成の仕組みと組み合わせます。
まず最初に、流用した仕組みで入力画像を 4,096 個のデータに凝縮して入力します。この部分はすでに学習が済んでいるので調整作業は不要です。画像処理部分の学習を省くことができることも、この組み合わせの大きなメリットです。
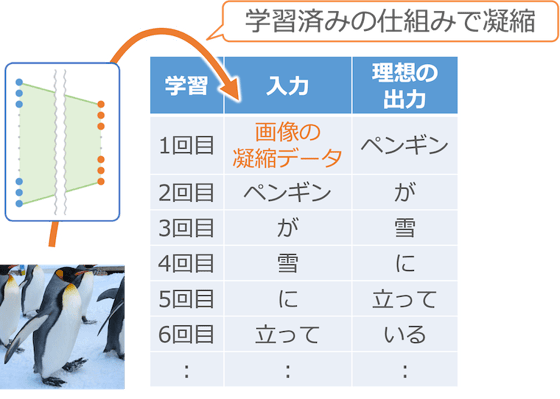
そして、1 回目は出力の単語が「ペンギン」になるように調整します。2 回目は「ペンギン」を入力して「が」が出力になるように、そして 3 回目は「が」を入力して「雪」が出力になるようにと、写真の説明文を生成するように調整していきます。
このように、先ほどの文章生成の仕組みと組み合わせて機械学習すると、写真の説明文を生成できるようになります。
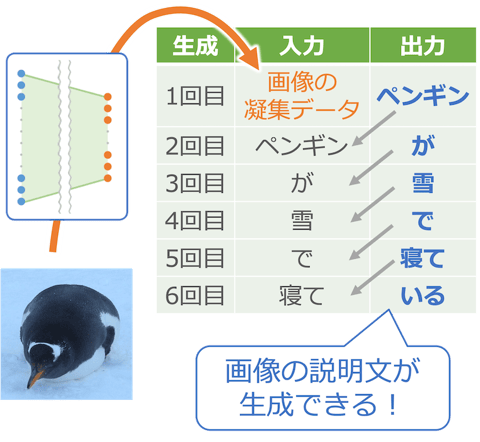
生成させる時は、最初に画像を 4,096 個の特徴データに変換して入力し、あとは出力で得られる単語を次々に入力に渡していきます。これで写真の説明文が生成されていきます。
このように別の学習済みの仕組みを組み合わせることで、機械学習の時間の短縮しつつできることが増やせます。
🙈読み飛ばしOK!
実際には、画像の凝縮データはニューラル ネットワークの中間部分に直接入力する形になっており、単語の入力とは別になっています。ここではイメージしやすいように、画像の凝縮データと単語が同じように入力されている表にしました。
この例では VGG16 を流用することで画像データを 4,096 個の情報に凝縮しましたが、このように情報を凝縮させる仕組みを「エンコーダー」(encoder)と呼びます。また、その凝縮した情報を利用して文章を生成させましたが、このように凝縮した情報から別の情報を生成する仕組みを「デコーダー」(decoder)と呼びます。
異なるエンコーダーとデコーダーを組み合わせることで、いろいろとおもしろいことができます。たとえば、日本語の文章をエンコーダーで凝縮して、その情報を利用して英文生成のデコーダーで文章を生成すれば日英翻訳ができます。また、文章をエンコーダーで凝縮して、その情報で画像生成のデコーダーを使えば、文章にあった絵を描かせることができます(絵を描かせる例は後述します)。
ただし、単純にエンコーダーとデコーダーを組み合わせても精度が上がらない課題は多くあります。エンコーダーが情報を一律で凝縮してしまうと、生成時に重要となる情報が薄まってしまうためです。また、エンコーダーとデコーダーを分けて考えるのではなく、入出力のデータの関連性を効率よく学習するための工夫も重要です。そこで、重要な情報や入出力の関係を効率よく学習できるように細胞のつなぎ方を工夫した「注意機構」(attention)という仕組みもよく使われます。
2017 年に発表された「Transformer」という仕組みは、エンコーダーとデコーダー、そして注意機構を組み合わせたものになっており、大規模言語モデル構築の基本になっています。
[画像と説明文の正誤判定]+[画像の繊細化]=文章から画像を生成!
写真データの情報を凝縮して、そこから説明文を生成する仕組みについてご説明しましたが、逆のことをやれば、説明文から写真を生成できるのではないでしょうか。それを実現したのが 2022 年に公開された Stable Diffusion です。
しかし、話はそれほど単純ではありません。入力された説明文をどのように凝縮するか、そして凝縮したデータからどのように繊細な画像を生成するのか、この 2 つの課題を克服する必要があります。
まず、入力された説明文の凝縮です。
凝縮は目的にあった仕組みを利用しないと精度が上がりません。前述の写真から説明文を生成する例では、VGG16 を流用して入力画像を凝縮しました。これがうまくいったのは「画像を分類する」という目的で学習された VGG16 が、説明文の生成に必要な情報もうまく凝縮してくれたためです。今回は絵を描くために必要な情報を、説明文からうまく凝縮してくれる仕組みが必要です。
Stable Diffusion では説明文を凝縮する部分に、CLIP という仕組みを利用しています。この CLIP は「写真と説明文の内容が一致しているかどうかを判定する」という目的で機械学習された仕組みで、写真データを凝縮する仕組み(下図の左半分)と説明文を凝縮する仕組み(右半分)が組み合わされており、左右の凝縮結果が一致するように左右それぞれを学習してあります。
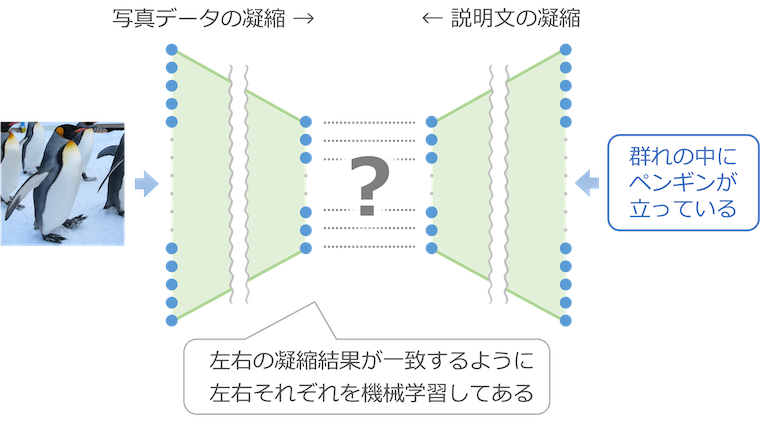
Stable Diffusion では、この CLIP の右半分を流用して、画像生成に必要な情報を説明文から凝縮しています。
続いて画像の生成です。Stable Diffusion では CLIP の右半分で凝縮した情報から繊細な画像を生成するために、次のような仕組みを使っています。
まず、機械学習につかう使うデータとして、大量の画像と、それを何度も繰り返して汚したもの(ノイズを加えて劣化させたもの)を準備します。

そして、汚した画像を入力、その汚す 1 つ手前の画像を理想の出力として機械学習します。

これで、汚れた画像を入力すると、そこから汚れを少し取り除いた画像を生成してくれる仕組みができあがります。得られた画像を繰り返し入力すれば、画像がどんどんきれいに繊細になっていきます。この仕組みを使うことで、CLIP の右半分で凝縮した情報から繊細な画像を作り出します。
🙈読み飛ばしOK!
このように、ノイズを加えたデータを用意して、それを戻せるように機械学習させていく仕組みを「拡散モデル」(diffusion model)と呼びます。
なお、Stable Diffusion では、画像に直接ノイズを加えて汚すのではなく、画像をまず凝縮して情報量を減らし、それに対してノイズを加えることで処理を効率化しています。ここではイメージしやすいように見た目が汚れていく画像を使いましたが、実際には目で確認できるような画像データとしては処理されていません。
ここからは、この 2 つの仕組みを組み合わせて機械学習します。
まず最初に、入力の文章を CLIP の右半分の仕組みで凝縮して入力に与えます。
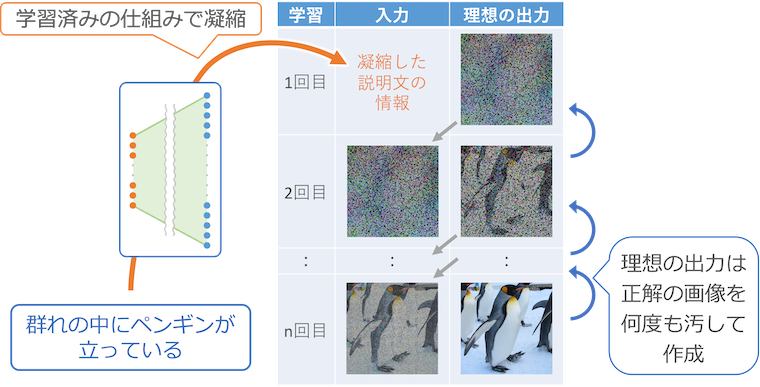
そして、1 回目の出力は、入力の文章に対応する理想の画像を何度も汚したものになるように学習します。2 回目は 1 回目の理想の出力がそれを汚す 1 つ前になるように、そして 3 回目は 2 回目の理想の出力がそれを汚すさらに 1 つ前になるように、と出力されたもの繰り返し入力すれば理想の繊細な画像になるように学習していきます。
このように、CLIP の右半分の仕組みと画像から汚れを取り除く仕組みを組み合わせて機械学習すると、入力した文章から繊細な画像が生成できるようになります。
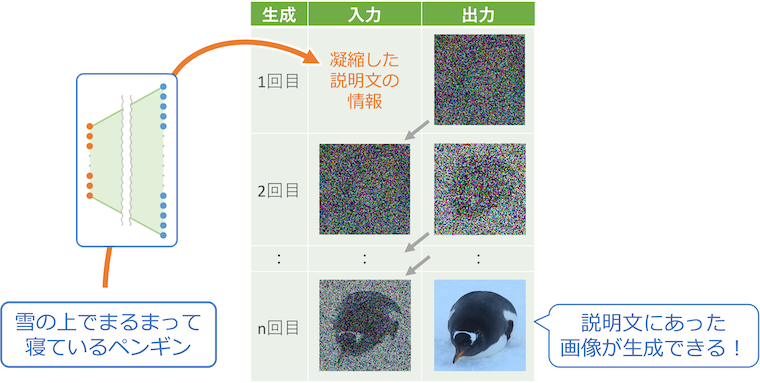
生成させる時は、最初に説明文をCLIP の右半分の仕組みで凝縮して入力し、あとは出力で得られる画像を繰り返し入力に渡していきます。これで説明文から繊細な画像が生成されていきます。
第 4 章のまとめ
- 細胞のつなぎ方の工夫で、できることが増やせます。
- 用途の異なる仕組みを組み合わせることで、さらにできることが増やせます。
- 学習済みの仕組みを流用することで、機械学習を効率化できます。
- これらの技術によって大量データの取り扱いができるようになり、人間のような文章を書いたり、写真のような繊細な画像を描いたりすることができるようになりました。
大量データを機械学習できるようになったことで、できることが急速に拡大し、2022 年終わりには人間のような自然な対話ができるチャットボットが登場しました。また、実施させたい作業を人間の言葉で指示できるようになったことにより、AI の活用方法がさらに拡大しています。
・
・
・
第 5 章 会話の仕組みとその活用
第 5 章では、自然な会話ができる仕組みと、AI の新たな活用の動向についてまとめます。
文章を生成する技術の進化
前章で夏目漱石の小説を例に文章を生成する仕組みをご説明しましたが、その後の改良によって、今では単純に文章の続きを生成するだけではなく、質問文に対して回答することも実用的になりました。このような能力の向上は、主にインターネット上から収集された膨大な文章を利用して、大量の細胞を複雑につないだ仕組みを機械学習することで実現されています。
仕組みの大規模化
第 2 章の手書き文字の認識でご説明した細胞のつなぎ方を学習するためには、 45,200 個の細胞間の伝わりやすさと 160 個の細胞自身の次に伝える境界の値の調整が必要でした。合計 45,360 個の値を機械学習により調整することで実現しています。
これに対して、たとえば 2020 年に発表された GPT-3 という文章生成の仕組みでは、インターネット上から 45TB の文章を収集して、そこから選別した 570GB の文章を使い、1,750 億個の値を機械学習によって調整しています。学習にかかったコストは数億円から数十億円と言われています。
2022 年に発表された PaLM では、調整した値の数が 5,400 億個になりました。さらに、2023 年 3 月に発表されて Microsoft の Bing や Office などへの搭載で話題になった GPT-4 では、値の数は非公開ながらも、さらに大量の値を学習しているものと思われます。
以下の図は、各仕組みが発表された時期(横軸)とその学習対象の値の数(縦軸)の関係です。仕組みの名前のカッコ内は調整している値の数で、単位は「M」が百万、「B」が十億です。
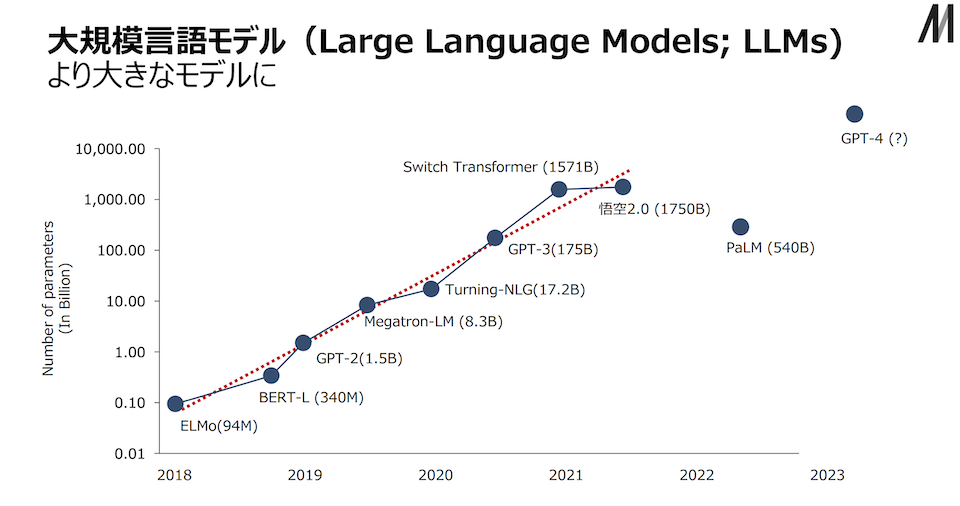 (出典)東京大学松尾研究室🔗「AIの進化と日本の戦略」より
(出典)東京大学松尾研究室🔗「AIの進化と日本の戦略」より
🙈読み飛ばしOK!
上の図にもありますが、大量のテキストデータを使って文章を生成できるように学習した仕組みを「大規模言語モデル」(LLM:large language model)と呼びます。
なお、2020 年に、学習する値の数と学習に使うデータ量、そして学習のための計算量を増やせば増やすほど、どんどん性能が上がることがわかりました。2023 年 3 月時点でも、その上限は判明していません。
また、ある計算量を境に性能が飛躍的に向上する現象も確認されました。以下の図は 3 種類の性能の試験(複雑な数学の問題、大学レベルの受験問題、単語の意味の特定)に対する結果で、横軸が学習のための計算量、縦軸が回答の正確さです。横軸の計算量があるポイントを超えると、性能が大きく向上することがわかります。
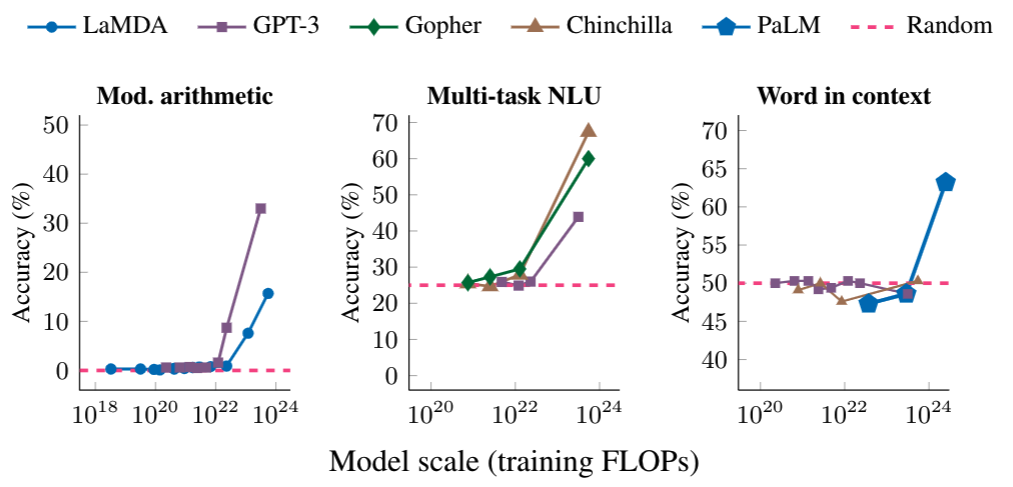 (出典)Google Research Blog
(出典)Google Research Blog
🔗「Characterizing Emergent Phenomena in Large Language Models」より
まだ、どのような性能が向上するのかは良くわかっていません。これからも、驚くような進化が続くものと思われます。
🙈読み飛ばしOK!
学習する値の数、学習に使うデータ量、学習のための計算量の 3 つを増やせば増やすほど性能が上がる法則をスケール則と呼びます。ただし、これは Transformer という仕組みにおけるもので、現在の主要な大規模言語モデルは Transformer をベースにしていますが、そうではないものには当てはまらない可能性があります。
なお、このスケール則の発見により、巨大 IT 企業による大規模言語モデルの規模の争いが激化しています。
会話の実現
文章生成の仕組みが進化したことで、質問文に対して回答することも実用的になりました。しかし、そのままでは人間のような会話はできません。インターネット上から収集された情報を元にしていますので、ウソを答えてしまうこともありますし、有害な情報を答えてしまうこともあります。また、人間の会話特有のくだけた表現に対する精度も高くはありません。
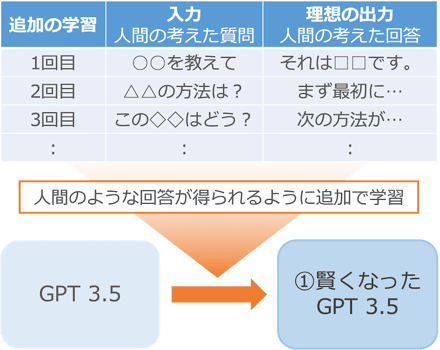
そこで、2022 年 11 月に公開された ChatGPT では、GPT-3.5 という文章生成の仕組みに対して、次のような追加の学習を行うことで人間のような会話を実現しています。
まず、ChatGPT に対する問いかけ文とその理想の回答文のセットを人間が大量に用意します。そして、それを使って GPT-3.5 に追加の学習を実施して調整します。これにより、人間の問いかけに対する回答精度の上がった①ができあがります。
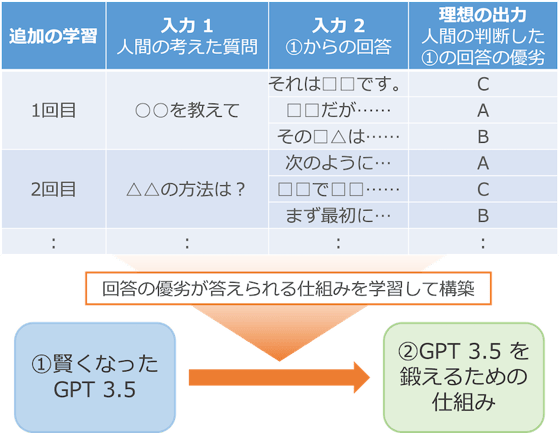
次に、この①をさらに自動で鍛えるために、壁打ちの相手を作ります。
①を複製して、質問と回答を入力したらその回答の良し悪しを出力する形に改造します。そして、質問文と①がその質問に対して回答した複数の回答文を入力とし、その出力が、人間が判断したその回答の良し悪しになるように学習します。ここでの人間による良し悪しの判断は、デマがないか、人や環境を傷つけないか、ユーザーの質問を解決しているかなどを評価軸にしています。
そして、②を壁打ちの相手にして①を鍛えます。①に質問を入力して答えさせたら、それを②がチェックして、その回答の良し悪しを判断します。そして、回答の質が悪い場合は、それを改善するために①を追加で学習します。人間の判断の代わりに②を使うことで①と②のやり取りを自動化し、ここをぐるぐる回すことで精度を高めています。
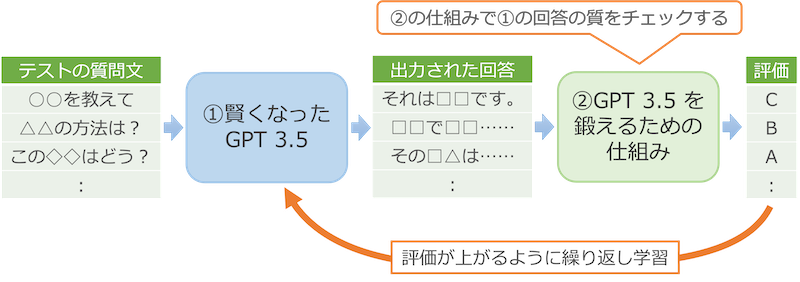
このようにして作り上げられたのが ChatGPT です。後半は自動的に学習していますが、前半は人間が大量の質問と回答を用意したり、人間が回答の良し悪しを判断したりと、人間らしい会話ができるように手間をかけて作り上げられています。
ChatGPT の能力は、ここで説明するよりもお試しいただく方が早いでしょう。ぜひ、実際に触って試してみてください。なお、使い方についてはここでは割愛します。「ChatGPT 使い方」などでインターネットを検索すると多くの解説が見つかりますので、そちらをご参照ください。
 ChatGPT の応答例
ChatGPT の応答例
🙈読み飛ばしOK!
①のように、既存の仕組みに対して追加の学習をして調整することを「ファインチューニング」(fine-tuning)と呼びます。既存の仕組みを再利用する際によく使われます。
また、最後の壁打ちによる調整は、第 3 章でご説明したような方法とは少し異なる「強化学習」という手法が使われています。これは、出力結果の正解を与えて調整するのではなく、出力結果に対する良し悪し(報酬と呼ばれます)を与えて、その良し悪しが最大になるように学習する手法です。
ChatGPT ではこのように、人間のフィードバックを元に仕組みを学習しています。この手法は「RLHF」(Reinforcement Learning from Human Feedback)と呼ばれます。
会話による AI の利活用
ChatGPT などの会話可能な仕組みによって、AI の常識が大きく変わり始めました。これまでの AI の調整は、AI の研究者やエンジニアによって実施されていましたが、会話可能な仕組みの場合は、その会話によっても調整ができます。
たとえば、指示の出し方を工夫するだけで回答の精度を上げることもできますし、必要な手順や情報を与えることで実施内容を増やすこともできます。2023 年 3 月時点では、インターネットを「ChatGPTでできること」などで検索すると、指示の出し方の工夫や活用方法を紹介するサイトが大量にヒットし、日々、新たな活用方法が発見されているような状態です。
会話可能な仕組みの場合、文章で質問したり指示をするだけで活用できます。つまり、みなさんの業務で AI を活用できるかどうかを、専門家に頼らずにご自身でも簡単に試せるようになってきたのです。
なお、今回ご紹介した ChatGPT は学習に使っているデータが数年前のものなので、最新のニュースなどには答えることができません。また、たとえば会話の流れで EC サイトの商品を検索して紹介したり、そのまま購入を指示することなどもできませんし、お使いの社内システムと連携して購入のための決裁申請フローを開始するといったこともできません。しかし、2023 年 3 月に ChatGPT の機能を拡張する仕組みの提供が始まりましたので、近い将来、ChatGPT が会話の内容に応じて様々なシステムと連携できるようになるでしょう。
会話できる AI の登場によって、今後の AI の利活用では、AI への指示の出し方の工夫や既存システムとの連携もポイントになっていくものと思われます。
第 5 章のまとめ
- 文書を生成する仕組みは、規模の拡大によって新たにできることが増えています。
- その仕組みをベースに追加の学習をすることで、人間のような会話も可能になりました。
- 会話できる仕組みの登場により、AI の新たな利活用が進むものと思われます。
・
・
・
おわりに
「そもそも AI とはなにか?」から始まり、2023 年 3 月時点の AI の利活用に関する状況までをまとめてみましたが、いかがでしたでしょうか。このお話しの中に、なにか 1 つでも貴社にとってヒントになることがありましたら幸いです。
なお、執筆中に ChatGPT が発表されて急遽第 5 章を追加しましたが、最近の AI の進化には目を見張るものがあります。この記事を投稿した翌日にはもう情報が古くなっているかも知れません。最新の情報ではありませんので、ご承知おきください。
最後までお読みいただき、ありがとうございました。
参考文献・Webサイト
(第 1 章)
フリー百科事典「ウィキペディア(Wikipedia)」.「人工知能」(最終閲覧日2022/12/19)
🔗https://ja.wikipedia.org/wiki/人工知能
(第 2 章)
フリー百科事典「ウィキペディア(Wikipedia)」.「形式ニューロン」(最終閲覧日2022/12/19)
🔗https://ja.wikipedia.org/wiki/形式ニューロン
フリー百科事典「ウィキペディア(Wikipedia)」.「MNISTデータベース」(最終閲覧日2022/12/19)
🔗https://ja.wikipedia.org/wiki/MNISTデータベース
斎藤 康毅.「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」.オライリー・ジャパン, 2016
🔗https://www.oreilly.co.jp/books/9784873117584/
(第 3 章)
斎藤 康毅.「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」.オライリー・ジャパン, 2016
🔗https://www.oreilly.co.jp/books/9784873117584/
日経BP総合研究所「ものづくり未来図」.「GAFAから部品メーカーまで、AIチップ大混戦」(最終閲覧日2023/1/29)
🔗https://project.nikkeibp.co.jp/atclmono/trend/013000008/
フリー百科事典「ウィキペディア(Wikipedia)」.「数学C」(最終閲覧日2023/1/29)
🔗https://ja.wikipedia.org/wiki/数学C
(第 4 章)
斎藤 康毅.「ゼロから作るDeep Learning ❷ ―自然言語処理編」.オライリー・ジャパン, 2018
🔗https://www.oreilly.co.jp/books/9784873118369/
THE ASIMOV INSTITUTE. 「THE NEURAL NETWORK ZOO」(最終閲覧日 2023/2/25)
🔗https://www.asimovinstitute.org/neural-network-zoo/
AI人工知能テクノロジー.「VGG16モデルを使用してオリジナル写真の画像認識を行ってみる」(最終閲覧日 2023/2/25)
🔗https://newtechnologylifestyle.net/vgg16originalpicture/
TRAIL (Tokyo Robotics and AI Lab).「CLIP:言語と画像のマルチモーダル基盤モデル」(最終閲覧日 2023/2/25)
🔗https://trail.t.u-tokyo.ac.jp/ja/blog/22-12-02-clip/
GIGAZINE.「画像生成AI『Stable Diffusion』がどのような仕組みでテキストから画像を生成するのかを詳しく図解」(最終閲覧日 2023/2/25)
🔗https://gigazine.net/news/20221006-visuals-explaining-stable-diffusion/
(第 5 章)
衆議院議員 塩崎彰久.「自民党AIの進化と実装に関するプロジェクトチーム」.
「第2回 2023年2月17日(金)テーマ:AI新時代の日本の戦略」資料.
東京大学松尾研究室.「AIの進化と日本の戦略 」(最終閲覧日 2023/3/27)
🔗https://note.com/akihisa_shiozaki/n/n4c126c27fd3d
InfoQ.「Googleが5400億パラメータのAI言語モデルPaLMをトレーニング」(最終閲覧日 2023/3/27)
🔗https://www.infoq.com/jp/news/2022/05/google-palm-ai/
Ryobot「ディープラーニングブログ」.「OpenAIが発見したScaling Lawの秘密」(最終閲覧日 2023/3/27)
🔗https://deeplearning.hatenablog.com/entry/scaling_law
Google Research Blog.「Characterizing Emergent Phenomena in Large Language Models」(最終閲覧日 2023/3/27)
🔗https://ai.googleblog.com/2022/11/characterizing-emergent-phenomena-in.html
@omiita.「話題爆発中のAI「ChatGPT」の仕組みにせまる!」(最終閲覧日 2023/3/30)
🔗https://qiita.com/omiita/items/c355bc4c26eca2817324
OpenAPI.「Introducing ChatGPT」(最終閲覧日 2023/3/30)
🔗https://openai.com/blog/chatgpt
Hirosato Gamo.「大規模言語モデルで変わるMLシステム開発」(最終閲覧日 2023/3/27)
🔗https://speakerdeck.com/hirosatogamo/da-gui-mo-yan-yu-moderudebian-warumlsisutemukai-fa
弊社では、IBM Watson や弊社の Cogmo シリーズを通じて、AI の導入やお客様の DX 推進をお手伝いしております。 ぜひお気軽にご相談ください。
ご相談先: Cogmo/AI関連お問い合わせ